May 2025 · 8 min read
Your Customer Exists in Six Places. None of Them Agree.
The duplicate identity problem is silently breaking your marketing, your metrics, and your money. Here's what's actually happening — and how the best operators fix it.
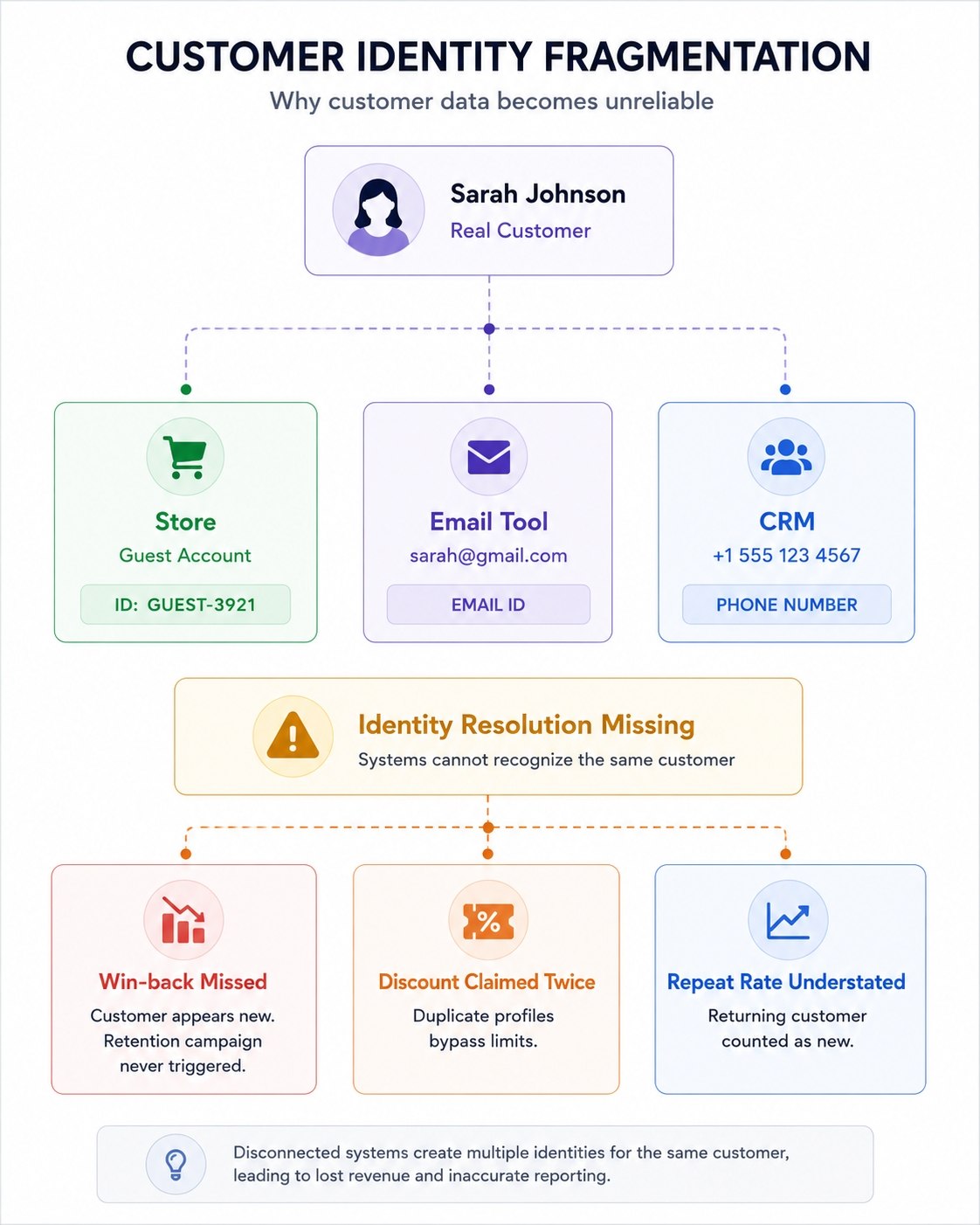
There's a customer in your database right now who has ordered from you three times.
Your store knows her as sarah.johnson@gmail.com. Your email tool knows her as a phone number she gave during an SMS signup. Your CRM logged her once as a guest checkout with no account attached.
Three records. One real person.
Your win-back campaign never reached her — she already existed in the system, just as someone else. Your "first order discount" got claimed twice — the second profile looked brand new. Your repeat purchase rate is lower than reality — half her orders are attributed to ghost profiles that don't connect to each other.
You didn't do anything wrong. Your tools didn't malfunction. This is just what happens when customer data lives across disconnected systems with no shared understanding of who anyone is.
This is called the duplicate identity problem. And it's happening in almost every store running more than two or three tools simultaneously.
Why This Happens
Every tool you add to your stack creates its own understanding of your customers — based on whatever identifier it can see.
Your store sees an email address at checkout. Your SMS tool sees a phone number at signup. Your ad platform sees a cookie or a device ID. Your support tool sees whoever emailed in.
None of these tools talk to each other. None of them know that the email address, the phone number, the cookie, and the support ticket all belong to the same person. So they each create their own record. And the same customer ends up living in your stack as four different people.
The technical term for this is identity fragmentation. The business term for it is expensive.
What It's Actually Costing You
This isn't just a data hygiene problem. It has direct revenue consequences.
Your win-back campaigns miss real customers. When a lapsed customer exists in your email tool as a separate profile from their order history, your "we miss you" sequence never fires — because the email tool doesn't know they've ever ordered.
Your discounts get abused without you knowing. A customer who creates a second profile — even accidentally, by using a different email — looks brand new to your system. First-order discounts, referral bonuses, free shipping thresholds — all of them get gamed by the same person appearing twice.
Your metrics lie to you. Repeat purchase rate, customer lifetime value, average order value per customer — every single one of these numbers is calculated on your customer records. If one real customer is split across three records, your repeat purchase rate looks lower than it is. Your LTV calculations are wrong. Your cohort analysis is wrong. You're making decisions based on a broken dataset.
Your ad spend leaks. You're paying to retarget people who already converted — because your ad platform's audience doesn't know someone who bought via email last week is the same person now browsing anonymously on mobile.
How Big Companies Solve This
Large enterprises — the Nikes, the Amazons, the Sephoras — have a category of software built specifically for this problem. It's called a Customer Data Platform, or CDP.
Tools like Segment, Salesforce Data Cloud, Amperity, and others are designed to do one thing: collect every identifier from every touchpoint, match them to a single master profile, and push that unified profile back to all downstream tools.
The technical approach uses two types of matching:
Deterministic matching — exact identifier matches. Same email address in two tools = same person. High confidence, clear logic. This is what most CDPs start with and what custom-built solutions can do reliably.
Probabilistic matching — "close enough" signals combined together. Same device, same location, similar browsing behavior, email that looks like a variation of a known address — not a definitive match, but statistically likely. Higher coverage, but a margin for error built in. Enterprise CDPs use machine learning to refine this over time.
The output of both approaches is the same: one master profile per customer, connected to every identifier they've ever used, accessible to every tool in your stack.
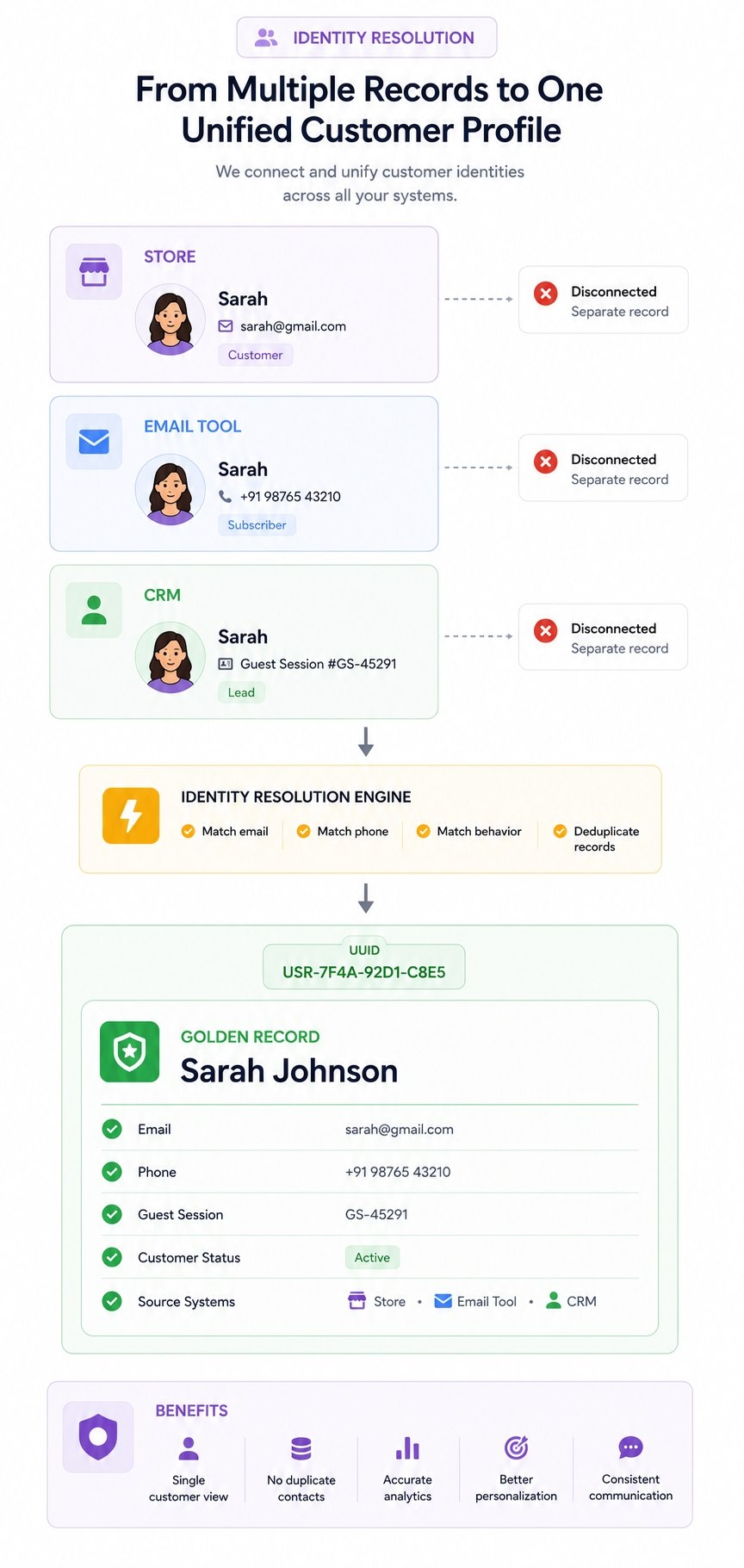
This is called a Golden Record in the industry. One authoritative, unified customer record that everything else reads from.
The Problem With Enterprise CDPs for Growing Stores
Here's the part nobody talks about.
Segment starts at $120/month but gets expensive fast at scale. Salesforce Data Cloud runs six figures annually. Amperity is built for enterprises with millions of customers and teams of data engineers to run it.
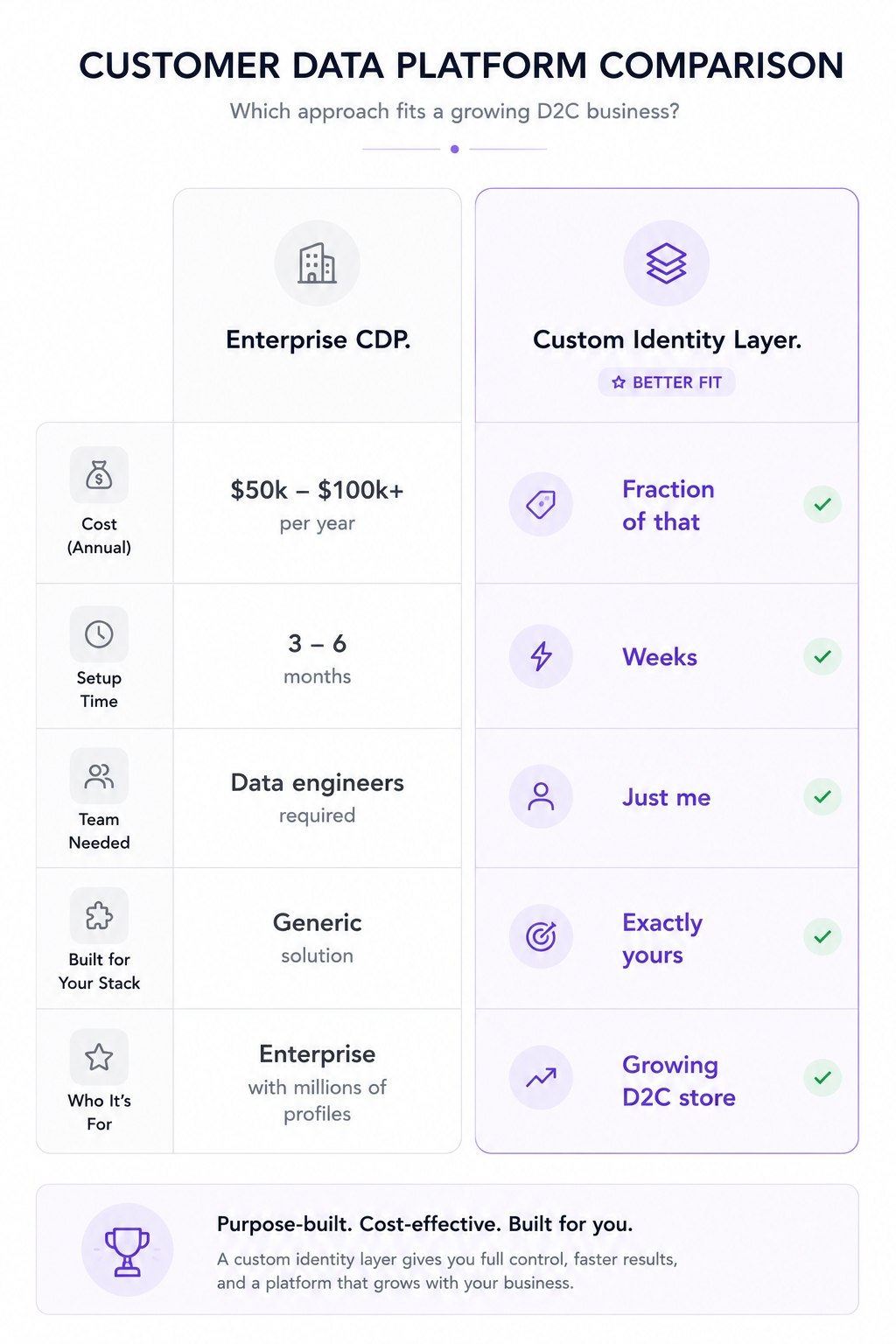
The implementation alone — just getting the thing connected to your stack — takes months and costs more than most growing D2C brands spend on their entire tech stack in a year.
For a store doing $500k to $5M in revenue, a full enterprise CDP is a sledgehammer for a nail. The problem is real. The solution is wildly oversized.
What these stores actually need is the core concept — one central identity layer, deterministic matching, unified profiles pushed to every tool — without the enterprise price tag and the six-month implementation project.
The Lightweight Architecture That Actually Works
Here's how I build this for growing D2C stores.
The central identity layer is a Supabase database — PostgreSQL under the hood — that stores one master record per customer. Every customer gets a UUID the moment they first interact with the store. Every identifier they use — email, phone, order ID, session ID — gets attached to that UUID.
The matching logic runs in n8n. Every time a new customer interaction comes in from any tool, n8n checks the identity database first: does this email already exist? Does this phone number already exist? If yes — attach the interaction to the existing UUID. If no — create a new record.
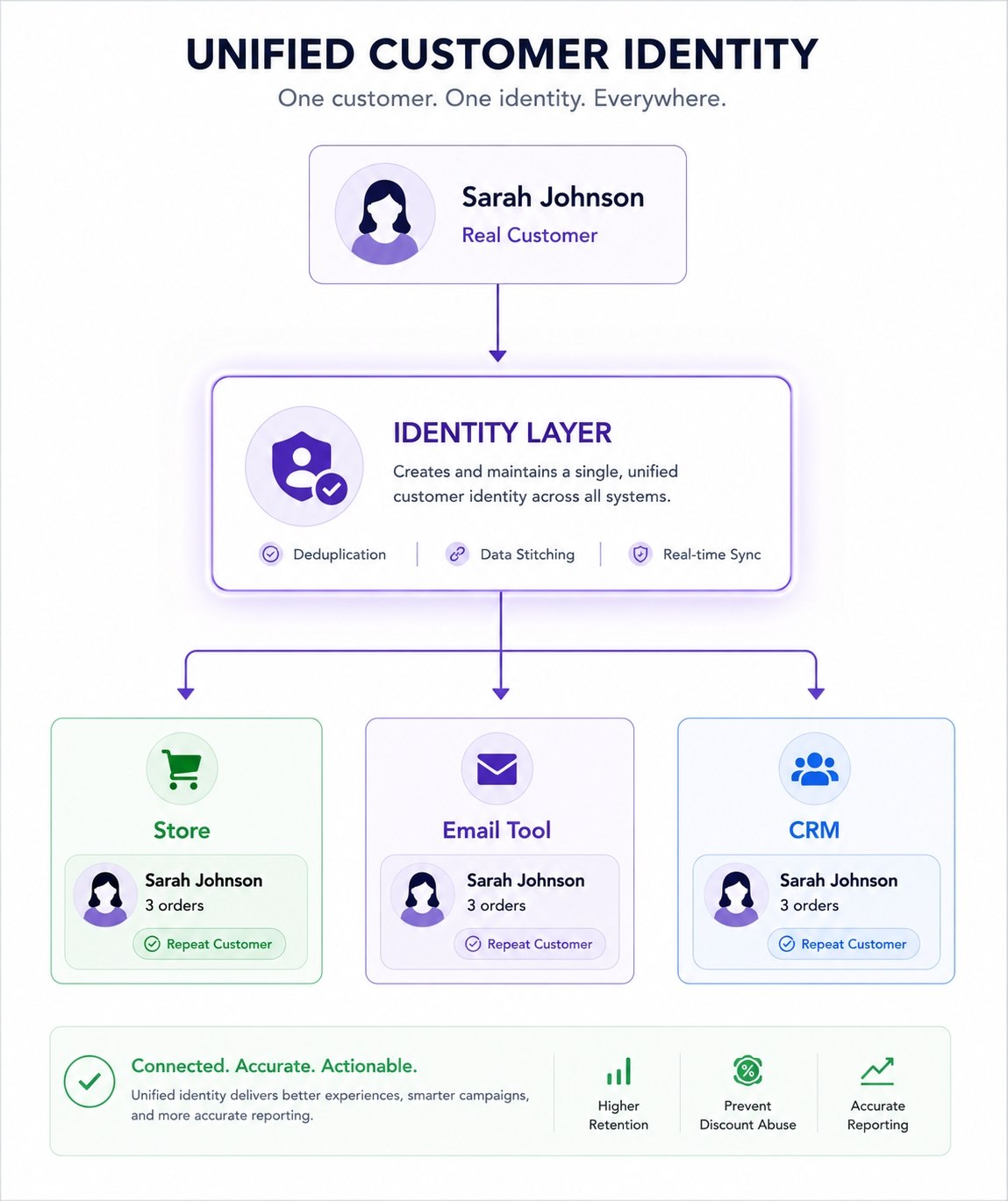
The sync layer pushes the unified profile back to every tool. Your email tool gets updated with the customer's full order history. Your CRM gets the correct lifetime value. Your ad platform gets a clean, deduplicated customer list.
The result is that every tool in your stack is working from the same understanding of who your customers are. Win-back campaigns reach real lapsed customers. Discount logic can check actual order history across all identifiers. Metrics reflect reality.
What This Solves — And What It Doesn't
I'll be direct about the limitations, because anyone selling you a magic solution to this problem is lying.
This works reliably for:
- Customers who use consistent identifiers — the same email to order and sign up
- Stores with a manageable, defined tool stack — store, email platform, CRM, ad platforms
- Deduplicating existing records with a one-time historical cleanup before the new system starts
This doesn't solve:
- Anonymous cross-device tracking — someone who browses on mobile and buys on desktop without logging in. Deterministic matching can't connect those sessions without a shared identifier. Probabilistic matching can get you closer but it's not a custom-build solution — that's where enterprise CDPs earn their price tag.
- Tools that don't allow external writes — some SaaS platforms are closed systems that won't let you push data in. If a tool won't accept a unified profile, it will keep creating its own records regardless.
The honest framing: this architecture solves 80% of the identity problem for a growing D2C store, at a fraction of the cost and complexity of an enterprise CDP. For the remaining 20% — cross-device anonymous tracking at scale — you eventually need a purpose-built tool. But most stores aren't there yet, and spending $100k/year on a CDP before you need it is just expensive.
What Becomes Possible When the Data Is Clean
This is the part I find most interesting.
Once every tool in your stack is working from a unified customer profile, a new category of things becomes possible.
AI that actually knows your customers. Right now, any AI-driven personalization you run is working from fragmented data. Recommendations based on incomplete purchase history. Segments built on partial profiles. When the identity layer is clean, AI models have a complete picture of each customer to work with — and the output gets dramatically more accurate.
Accurate lifetime value. LTV calculated on unified profiles is a completely different number from LTV calculated on fragmented records. For many stores, the real LTV per customer is 30-40% higher than what their dashboard shows — because repeat purchases are split across ghost profiles.
Attribution you can trust. When your ad platform knows which customers have already converted — based on unified profiles, not just cookies — your lookalike audiences get better, your suppression lists work properly, and your ROAS numbers stop lying to you.
Retention that actually retains. Win-back campaigns, re-engagement flows, loyalty triggers — all of these depend on knowing who your real lapsed customers are. With a unified identity layer, you're working from reality instead of a fragmented approximation of it.
The Bigger Picture
The stores that win at retention and personalization over the next few years aren't going to be the ones who spent the most on the most expensive tools.
They're going to be the ones who got their data foundation right first.
Identity resolution isn't a feature you add. It's a layer you build underneath everything else. And once it's there, every tool in your stack gets smarter — because they're all finally working from the same truth.
I build identity layers, data infrastructure, and AI-powered automation systems for D2C and e-commerce brands. If your customer data is fragmented across six tools and none of them agree — that's exactly the kind of problem I fix.
Think your store has this problem? It probably does. Let's find out.